Learning Rust - Implementing a bloom filter
I recently started working through the Rust book. After working through the first half or so, I wanted to implement something outside of the context of the tutorial to get more practice with the language. I’ve also wanted to implement a bloom filter for a while, so I killed two birds with one stone and implemented one in Rust! This post covers that implementation.
Bloom filter?
Bloom filters are a space efficient data structures that are able to answer the question “have I seen this value before?”. An alternative solution would be to use a set; you could insert each element you encounter and check future elements against those contained in the set. That’s got O(1) time complexity, but because the set has to store every element you insert, its memory footprint also grows with each new element. Bloom filters, on the other hand, store hashes of inserted values, which allows them to not grow at all when elements are inserted.
Bloom filters aren’t some magic solution to data storage, though. Once a value is inserted to a bloom filter it can’t be read back out; the only operations on a bloom filter are insert and contains. Bloom filters are also probabilistic; contains can’t always give a definitive answer. It’ll never have a false negative - if contains returns “no”, the bloom filter definitely doesn’t contain the element. False positives, on the other hand, are a normal part of operation for a bloom filter. As such, the alternative response to “no” is “maybe”; where “maybe” means that the bloom filter might contain the element.
bloom_filter.insert('foo')
bloom_filter.contains('bar') -> no
bloom_filter.contains('foo') -> maybe
How do?
A bloom filter consists of an array of m underlying bits. When inserting a value, k separate hash functions are applied to the value, each of which results in a value in [0, m). Each of those values represents a position in the bit array - to insert a value, the bloom fliter sets all of the bits in those positions to 1. Outside of hash collisions, every value inserted to the bloom filter will have a unique combination of bits that it sets to 1.
To check whether a bloom filter contains an element, we can re-hash the value to once again generate k values (using the hash functions). If the value was inserted previously, all of the bits in those k positions would already be 1; therefore, if any are 0, we know that the value has never been inserted to the bloom filter.
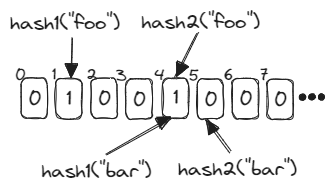
In the example below, we insert foo to a bloom filter where k = 2. The two values that it hashes to are 1 and 4, so those bits are set to 1. To check whether bar is in the bloom filter, we calculate its hash values (4 and 5 in this example). Because 5 isn’t set, we know that bar hasn’t been inserted into the bloom filter:
My implementation
You can find my full implementation here. This section will take a quick run-through some of the interesting bits. The BloomFilter struct contains three fields; bits contains the underlying array of bits in the form of a BitVec, hasher_count is k (the number of hash functions), and hasher_range_in_bits defines the length of the bit vector. The length of bits is always 2ᵏ; the reason for that will become apparent later:
struct BloomFilter {
bits: BitVec,
hasher_count: usize,
hasher_range_in_bits: u32,
}
I’ll skip over the build method, which builds a new BloomFilter and take a look at add and is_present. They implement the logic I described above; self.hash(t) returns the list of positions that should be 1 for a given value t. add sets the bits in those positions to 1 while is_present checks the bits in the positions to confirm whether the value’s present in the bloom filter yet:
fn add<T: AsRef<[u8]>>(&mut self, t: &T) {
let t_hash = self.hash(t);
for i in 0..t_hash.len() {
self.bytes[i] = self.bytes[i] | t_hash[i]
}
}
fn is_present<T: AsRef<[u8]>>(&self, t: &T) -> BloomCheckResult {
let t_hash = self.hash(t);
for i in 0..t_hash.len() {
if self.bytes[i] & t_hash[i] != t_hash[i] {
return BloomCheckResult::No;
}
}
BloomCheckResult::Maybe
}
The hash function itself takes an object that can be serialized as an array of bytes and returns the vector of k positions:
fn hash<T: AsRef<[u8]>>(&self, t: &T) -> Vec<usize> {
...
}
It then uses a SHA512 hasher to hash t1. SHA512 hashes are 64 bytes (512 bits) long and are represented as vectors of bytes, stored in full_bytes here.
fn hash<T: AsRef<[u8]>>(&self, t: &T) -> Vec<usize> {
let mut hasher = Sha512::new();
hasher.update(&t);
let full_hash = hasher.finalize();
...
}
The 64 bytes of the SHA512 hash are way more than we need for the bloom filter, but rather than using k separate hashers, this bloom filter takes slices of the SHA512 hash and treats those as the output of the k hashers. Each slice is of length hasher_range_in_bits (k), which makes it the binary representation of a number in [0, 2ᵏ). In the example earlier, if we had hasher_range_in_bits = 8, the first two bytes of the SHA512 would have looked like:
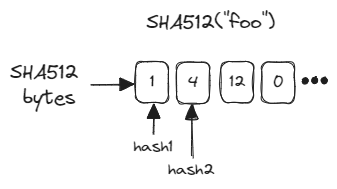
The fact that each hasher generates values in [0, 2ᵏ) is also the reason that the underlying bit vector’s length is always a power of two. Allowing arbitrary bit vector lengths would mean potentially having to wrap the hashers’ values to stay within the bounds of the bit vector, which I didn’t feel like doing. Here’s an animation that might make it clearer what’s happening here’. This animation uses hasher_range_in_bits = 4.
I defined computed_hash to hold the vector of positions that’s returned from the hash method and full_hash_ptr to hold a pointer to positions in the SHA512 hash as it’s split up:
...
let full_hash = hasher.finalize();
let mut computed_hash: Vec<usize> = vec![0; self.hasher_count];
let mut full_hash_ptr = 0;
for bloom_hasher_index in 0..self.hasher_count {
...
}
computed_hash
To find the bits that apply to a given hasher, the algorithm walks full_hash_ptr along the bits of the SHA512 hash and adds them into hasher_value, shifting the bits left as it adds each value. It finds the byte that’s currently being worked on by dividing the full_hash_ptr by 8. full_hash_ptr % 8 is then the bit within the byte that’s being considered. To extract that bit from the byte, it build a bitmask with a 1 in the position of the bit (so for bit 3, we’d build 00010000) and bitwise AND it with the byte. If the result is non-zero, the bit is 1.
Once the value for the current hasher’s been fully computed, it gets added to the final vector.
for bloom_hasher_index in 0..self.hasher_count {
let mut hasher_value: usize = 0;
for _ in 0..self.hasher_range_in_bits {
let byte_index: usize = (full_hash_ptr / 8).try_into().unwrap();
let bit_in_byte = full_hash_ptr % 8;
let bit_mask: u8 = 2_u8.pow(bit_in_byte);
let bit: bool = full_hash[full_hash.len() - byte_index - 1] & bit_mask != 0;
hasher_value = (hasher_value << 1) + (bit as usize);
full_hash_ptr += 1;
}
computed_hash[bloom_hasher_index] = hasher_value;
}
Conclusions and another manimation
Bloom filters are actually fairly straightforward, but implementing one was a fun first stab at getting comfortable with Rust. I’ve also been playing with Manim, so to close out this post, here’s a little animation of an 8 bit bloom filter in action:
Footnotes
-
There are many alternatives, but because I don’t particularly care for performance optimisation in this project, SHA512 works just fine and
sha2is the first crate that appears when I search for “hash”. ↩